In my last post “the serverless API” I explained how an API could be build without any infrastructure to begin with. To prove my point I started building an API on top of an existing homepage.
Mintos is a service I use for investing into p2p loans. If you want further information about Mintos head over to their FAQ section.
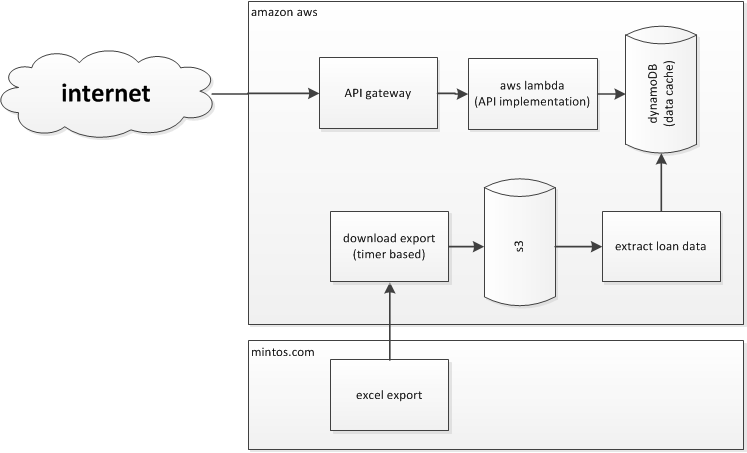
overview
what data does it expose
Since the export of data from Mintos is somewhat limited, I settled for what I could get without putting too much effort in it. So there is:
- primary market data (currently open loan to bid on)
- secondary market data (existing loans offered for trading)
- the loan book (complete history of loans)
step 1 - fetch
Fetching data from a remote site is nothing to complicated. I implemented a lambda function which got called 3 times a day which just downloads the current Mintos Excel export to Amazon S3.
step 2 - extract loan data
Since Amazon Lambda functions a rather flexible I attached a java function to my S3 store which had the ability to parse the Excel sheet and exports single entry Items, which I than enter into DynamoDB. So far I only translate every value into a DynamoDB key/value-pair.
step 3 - define an API structure
Amazon uses JSON-schema as a basis for their API structure. So I now had to define a structure based on the exported data in link that to the corresponding API implementation.
step 4 - implement API Lambda for data retrieval
Implement a short nodejs program which glues the internal DynamoDB to the public API schema.
further notes
So far I didn’t find any method on how to expose any documentation for the API. Although this shouldn’t be that hard (especially since the implementation is already shema-based), Amazon does seem to have a default way to do this.
The API so far is rather slow, since I’m keeping the IO-quotas low. This is intentional, since this is only a POC (rather low cost in my terms means, under 1 Euro a month hosting).