Converting a CSV to ORC files usually takes a Hadoop cluster to perform the task. Since I only wanted to convert files for later uploading into an existing cluster, I tried some different approach. Searching for some tool to do the task, I arrived at Apache NiFi.
Here is the flow I used to transform my data.
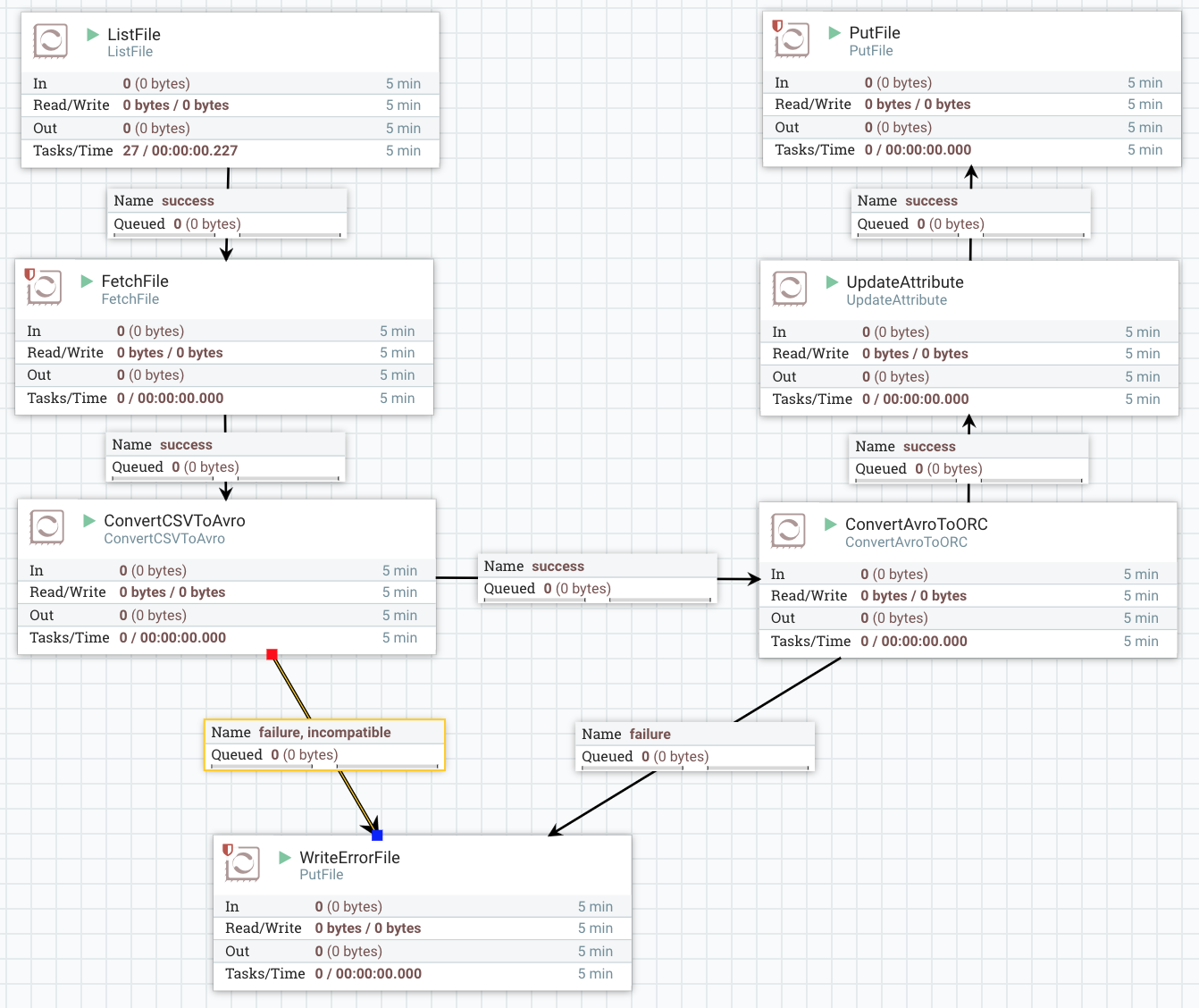
- step 1 - list all exiting CSV files
- step 2 - read each file into memory
- step 3 - convert content into AVRO
- sadly AVRO needs a schema of you data to do the actual conversion. so here is the simple schema I used for my data:
{
"name": "jobs",
"type": "record",
"fields": [
{"name":"jobStart","type": "string"},
{"name":"jobEnd","type": "string"},
{"name":"logId","type": "string"},
{"name":"corrid","type": "string"},
{"name":"parentid","type": "string"},
{"name":"jobId","type": "string"},
{"name":"process","type": "string"},
{"name":"machine","type": "string"},
{"name":"duration","type": ["null","long"]},
{"name":"status","type": "string"},
{"name":"domain","type": "string"},
{"name":"deployment","type": "string"},
{"name":"engine","type": "string"}
]
}
- step 4 - convert AVRO to ORC
- step 5 - UpdateAttribute: set the target filename
- step 6 - write the ORC file to the target location
Here is the NiFi flow I used. You will have to change the file locations and data schema to really use it.
[CsvToOrc template][1]
[1]:{{ site.url }}/assets/CsvToOrc.xml