This is a cross-posting from downtozero.cloud
The more our little project progresses, the more code we produce. And like most of our community these days, we host our code on GitHub.
So during development we discussed the implications of a DownToZero architecture for something like a GitHub process. We quickly identified two types of actions that need to be performed on the infrastructure.
The first is the CI build, which should always provide immediate feedback to the developer. It checks for compliance as well as code integrity and is usually deeply involved in the development process. These jobs are time-sensitive because someone is usually waiting for them.
The second category we identified is a little different. With the rise of dependabot and other security scanners, we saw more and more pipelines being triggered by these bots. The thing about that is, we want to run the pipeline to check our dependencies and keep our code base up to date, but at the same time, no one is waiting for those pipelines. So it wouldn’t make any difference if those pipelines were delayed.
So let us look at the second category and see if we can build something within GitHub. Well, GitHub allows anyone to attach self-hosted runners to any project (hosting your own runners). If you look at the process, it is relatively straightforward, download the runner, attach it to your organization or repo and then run the shell script. There’s also a little helper that makes this runner into a systemd service, so we don’t have to start and stop the service ourselves.
Looking at the job distribution, GitHub says that the queued job is held for 24 hours. Within that time frame the job has to be picked up or it will timeout. So 24 hours is technically enough time to wait for the sun to come up, regardless of when the job was spawned.
With that being covered, we started to look at our local setup and how we can achieve such capacity planning. Our current setup looks like this.
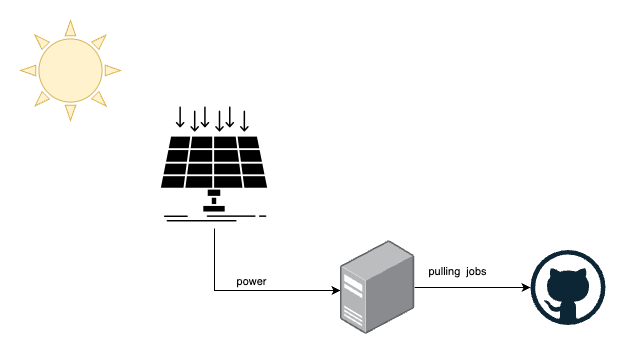
- we have solar panels that produce energy
- we have local machines that can consume that energy and have internet access
- GitHub provides the persistent job queue for our runner
We don’t have any battery storage attached to it, because that would make the whole system more expensive and complex.
All metrics, like the energy output of the solar panel or the energy consumption of the servers are tracked by independent tasmota devices (CloudFree EU Smart Plug).
So we hooked everything up. For convenience, we installed a ubuntu 22.10 (the same used for the GitHub hosted runner) on our machines. We also installed the toolchain we needed, such as rustup, gcc-musl, protobuf.
Now, we wrote 3 independent systemd services.
1) Dtz-Edge Service
The first service is always running and reads the energy output from HomeAssistant (this is where our energy data is aggregated). It also takes into account what other devices are currently running and how much energy they are already consuming. It then implements the following state model:
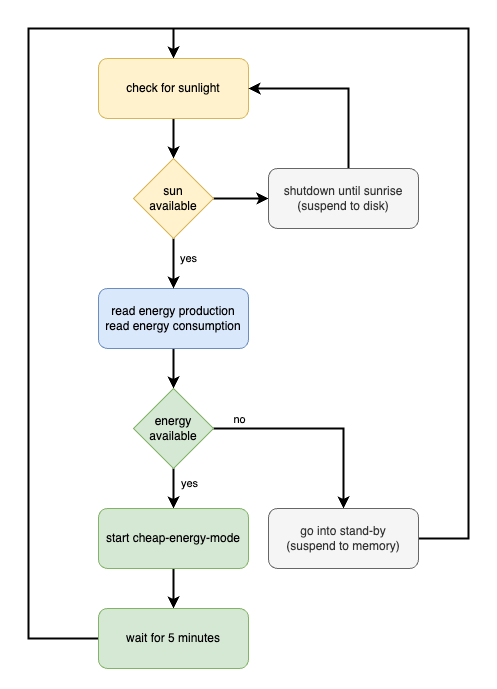
Systemd Service definition
[Unit]
Description=dtz edge Service
[Service]
Type=simple
WorkingDirectory=/root/dtz-edge
ExecStart=!/root/dtz-edge/busy.sh
Restart=always
[Install]
Alias=dtz-edge
WantedBy=multi-user.target
busy.sh shell script (shortened version)
#!/bin/bash
for (( ; ; ))
do
POWER=`curl -H 'Authorization: Bearer token1' -H "Content-Type: application/json" http://192.168.178.76:8123/api/states/sensor.solar_panel_energy_power 2> /dev/null | jq -r .state`
METER=`curl -H 'Authorization: Bearer token1' -H "Content-Type: application/json" http://192.168.178.76:8123/api/states/sensor.tasmota_energy_power_4 2> /dev/null | jq -r .state`
SALDO=$((POWER - METER))
echo "Saldo: $SALDO (solar: $POWER)"
CURRENT_HOUR=`date +%H`
if [ $CURRENT_HOUR -gt 17 ]; then
service cheap-energy stop
service actions.runner.DownToZero-Cloud.dtz-edge1 stop
echo "sleep till tomorrow (10h)"
rtcwake -m disk -s 36000
fi
if [ $SALDO -gt 70 ]; then
echo "more then 70: $SALDO"
service cheap-energy start
service actions.runner.DownToZero-Cloud.dtz-edge1 start
sleep 300;
else
service cheap-energy stop
rtcwake -m mem -s 660
fi
done
2) Cheap-Energy Service
This service only holds the state that cheap energy is available. So when this systemd-service is running, it means there is energy available, when it is stopped, all workers should shut down. So we use this service as a proxy to make management easier.
[Unit]
Description=cheap energy
[Service]
Type=simple
WorkingDirectory=/root/dtz-edge
ExecStart=!/root/dtz-edge/cheap-energy.sh
Restart=always
[Install]
Alias=cheap-energy
WantedBy=multi-user.target
The script we run in here is just a sleep command.
#!/bin/bash
sleep infinity
3) GitHub Runner Service
We followed the instuctions provided by GitHub and installed the runner as a systemd service.
sudo ./svc.sh install
This already gave us the correct service definition and the only thing we needed to change was the service dependency line. Because now we want this service to run whenever the cheap-energy-service is running, and also to stop this service when cheap-energy-service is stopped.
So we changed our service definition (actions.runner.DownToZero-Cloud.dtz-edge1.service) to include the BindsTo description.
[Unit]
Description=GitHub Actions Runner (DownToZero-Cloud.dtz-edge1)
After=network.target
BindsTo=cheap-energy.service
[Service]
ExecStart=/home/user1/gh-dtz-org/runsvc.sh
User=user1
WorkingDirectory=/home/user1/gh-dtz-org
KillMode=process
KillSignal=SIGTERM
TimeoutStopSec=5min
[Install]
WantedBy=multi-user.target
Now that we have the hardware part of the solution set up, let’s get back to the GitHub side.
We now have 2 types of runners in our GitHub UI. One is the GitHub-hosted runner, that we want our type 1 task to run on, and one is our dtz-edge pool that only comes up when there is enough solar power.
Let us split our pipeline definitions.
For the type 1 jobs, everything can stay like a normal GitHub pipeline.
name: build
on:
workflow_dispatch:
push:
branches:
- main
jobs:
build:
permissions: write-all
runs-on: ubuntu-latest
For the type 2 jobs, so job we want to run delayed on the solar powered machines, we just need to define the on-trigger section to include for scenarios that should be supported here. In our case we started with doing this for all pull-requests. Then the only thing that needs to be changed is the runs-on statement. Here we placed our newly generated runner.
name: pr
on:
workflow_dispatch:
pull_request:
jobs:
test:
name: coverage
runs-on: self-hosted
So now whenever dependabot sends us some updates to merge, or some other bot wants to check tests and code coverage, those jobs will run whenever we have the resources to do so.
As an added bonus, we also do no longer have to pay for these extra runners. On-prem runners are free (in the sense of GitHub pricing).