This post is a cross-post from Down to Zero. Canonical source: https://downtozero.cloud/posts/2025/pr-reviews/
We love automation. We use it to power our infrastructure, to scale workloads down to zero, and—increasingly—to shrink the amount of human attention needed to ship high-quality code. One place that still felt stubbornly manual was pull-request reviews. Between Cursor as our IDE, ChatGPT/Codex for prototyping, and gemini-cli for quick checks, our local workflows were fast—but CI still waited for a human.
So we asked a simple question: could we let a large language model read the diff, spot issues, and comment directly on the PR?
Turns out: yes. It took just a few lines of GitHub Actions glue to get helpful, structured reviews on every pull request.
The goal
We weren’t trying to replace humans. We wanted a first pass that:
- reads the actual diff of a PR (not the entire repo),
- points out obvious mistakes and risky changes,
- suggests small refactors or missing tests,
- categorises findings by priority,
- and posts results right where we already look: in the PR conversation and the Actions summary.
If a change is fine, we want the bot to simply say so and get out of the way.
The tools in our stack
- GitHub Actions for CI orchestration.
- Cursor (our day-to-day IDE).
- ChatGPT/Codex for ideation and quick off-line reviews.
@google/gemini-cliinside CI to run the automated review step.- The GitHub CLI (
gh) to comment on the PR. - A small but important ingredient: a prompt that steers the model to produce useful, actionable feedback.
The workflow, end to end
Here’s the full Action we’re running. Drop it into .github/workflows/gemini-pr.yml:
name: gemini-pr
on:
workflow_dispatch:
pull_request:
jobs:
build:
permissions: write-all
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
with:
submodules: 'true'
fetch-depth: 0
- uses: actions-rust-lang/setup-rust-toolchain@v1
with:
components: rustfmt, clippy
cache: false
- uses: actions/setup-node@v4
with:
node-version: 20
- name: install gemini
run: |
npm install -g @google/gemini-cli
- name: gemini
run: |
echo "merging into ${{ github.base_ref }}"
git diff origin/${{ github.base_ref }} > pr.diff
echo $PROMPT | gemini -a > review.md
cat review.md >> $GITHUB_STEP_SUMMARY
gh pr comment ${{ github.event.pull_request.number }} --body-file review.md
env:
GEMINI_API_KEY: ${{ secrets.GEMINI_API_KEY }}
GH_TOKEN: ${{ secrets.GITHUB_TOKEN }}
PROMPT: >
please review the changes of @pr.diff (this pull request) and suggest improvements or provide insights into potential issues.
do not document or comment on existing changes, if everything looks good, just say so.
can you categorise the changes and improvesments into low, medium and high priority?
Whenever you find an issue, please always provide an file and line number as reference information. if multiple files are affected, please provide a list of files and line numbers.
provide the output in markdown format and do not include any other text.
What each part does
-
Checkout with
fetch-depth: 0so we can diff against the PR’s base branch reliably. -
Rust toolchain installs
rustfmtandclippybecause our repos often include Rust code; those run elsewhere in our pipeline, but keeping toolchain setup here avoids surprises. -
Node is required for the
gemini-cli. -
We install
@google/gemini-cliglobally inside the runner. -
We create a diff file:
git diff origin/${{ github.base_ref }} > pr.diffThis ensures the model sees only the changes under review.
-
We pipe the prompt into
gemini -a(the CLI reads@pr.diffinline as a file reference) and capture the model’s markdown output intoreview.md. -
We append the review to the Job Summary (
$GITHUB_STEP_SUMMARY) so it’s visible in the Actions UI. -
We comment on the PR using
gh pr comment … --body-file review.md.
The prompt that makes it useful
LLM outputs are only as good as the instructions. Ours keeps things practical:
- Scope: Only review what changed. Don’t re-document the repository.
- Signal: Say “looks good” when there is nothing to add. No forced creativity.
- Actionability: Always include file + line numbers for findings.
- Priorities: Group by low / medium / high to help reviewers scan quickly.
- Format: Markdown only, so it pastes cleanly into PR comments and renders well in the summary.
We iterated a bit to reach this. The most impactful tweaks were: insisting on file/line references and forbidding extra prose.
What the review looks like
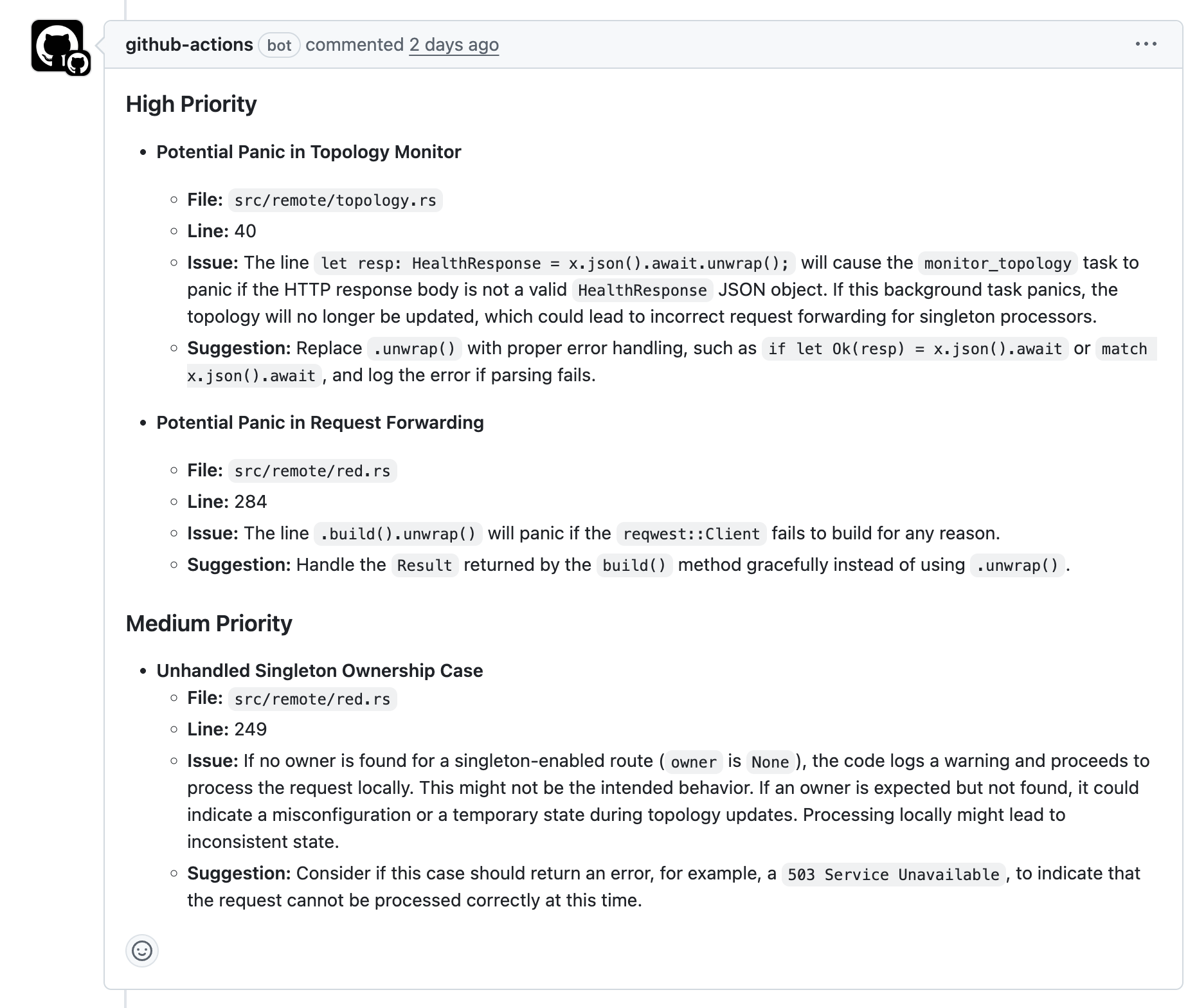
On a typical PR, we see sections like:
- High: Security-sensitive changes, broken error handling, missing input validation, accidental secrets, or removed tests.
- Medium: Edge cases, concurrency risks, questionable error messages, non-idiomatic Rust/Go/TS that could bite later.
- Low: Naming, comments, small refactors, or suggesting a short test to lock a behaviour.
If everything’s fine, we get a one-liner: “Looks good.” Perfect—that’s exactly what we want.
Gotchas and practical notes
- Secrets: You need
GEMINI_API_KEYandGITHUB_TOKENin repo or org secrets. Keep scopes tight. The Action setspermissions: write-allbecause it posts a comment; restrict this if your policy requires it. - Diff source: For complex merges,
git diff origin/${{ github.base_ref }}gives the right context. If your workflow fetches only the merge commit, make sure the base branch is available or adjust togithub.event.pull_request.base.sha. - Forks: If you accept PRs from forks, review how you handle secrets. You may want to run this on
pull_request_targetwith careful hardening, or gate the review behind labels. - Noise control: We found it useful to let the model say nothing beyond “looks good” when a change is trivial. That alone drops reviewer fatigue.
- Costs and quotas: Model calls aren’t free. We cap the size of the diff we send and run this only on
pull_request(not every push). - Privacy: You are sending your diff to an external model provider. If your code is sensitive or under export restrictions, assess risk and choose a provider/deployment model that fits your compliance needs.
Why this matters (beyond convenience)
Automated reviews make humans more selective with their attention. We spend less time on “rename this variable” and more time on architecture, data flows, and security boundaries. That means:
- Faster feedback loops for contributors.
- Fewer review cycles on nitpicks.
- A cleaner commit history with problems caught earlier.
- More time for the sustainability work we actually care about—like shaving watts off a service or reducing network egress.
It’s also surprisingly good at consistency. An LLM won’t forget the agreed-upon error-handling pattern between services or our preferred log structure; it applies those checks uniformly on every PR.
Variations you might try
This pattern works with almost any model or CLI. A few easy extensions:
- Multi-model voting: Call two models with the same prompt and keep only findings they agree on.
- Language-aware passes: If your repo mixes languages, run language-specific prompts (e.g., one tuned for Rust with clippy hints, one for TypeScript).
- “Fail on High” gates: Use a small parser to detect a “High” section and flip the job to
failedto block merges until addressed. - Inline review: Convert file/line references into GitHub review comments (the
ghCLI supports this) for even tighter feedback. - PR label control: Only run when a maintainer adds a
ai-reviewlabel, or auto-add aneeds-attentionlabel when high-priority findings appear.
Results so far
- Shorter review cycles on straightforward changes.
- Cleaner diffs because contributors fix low-hanging items before a human ever looks.
- Better onboarding: new teammates get concrete advice that mirrors what senior reviewers would say.
- No drama: if the bot has nothing to add, it’s quiet.
None of this replaces a human approving a merge. It’s a lightweight filter that pays for itself on day one.